
神经网络与深度学习 第二章
深入浅出神经网络与深度学习 第二章:反向传播算法工作原理
1. 一种基于矩阵计算神经网络输出的快速方法
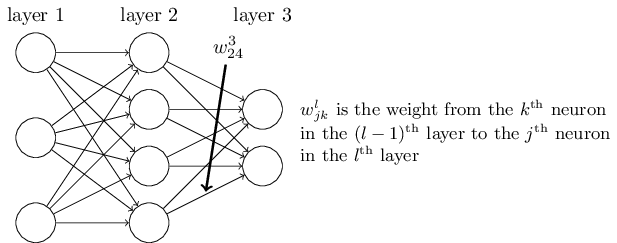
首先给出网络中权重的清晰定义。 表示从 () 层的 个神经元到 层的 个神经元的链接上的权重。例如,下图给出了网络中第 2 层的第 4 个神经元到第 3 层的第 2 个神经元的链接上的权重:
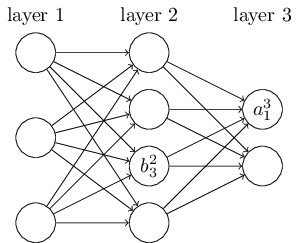
网络的偏置和激活值也会使用类似的表示。 表示在 层第 个神经元的偏置, 表示 层第 个神经元的激活值。下面的图清楚地解释了这样表示的含义:
其中求和是在 层的所有 个神经元上进行的。为了用矩阵的形式重写这个表达式,我们对层 都定义一个权重矩阵 。权重矩阵 的元素正是连接到 层神经元的权重,更确切地说,在第 行第 列的元素是 。类似的,对层 ,定义一个偏置向量 。偏置向量的每个元素其实就是前面给出的 ,每个元素对应于 层的每个神经元。最后,我们定义激活向量 ,其元素是那些激活值 。
方程可以写成简洁的向量形式,如下所示:
在使用方程(25)计算 的过程中,我们计算了中间量 。这个量其实是非常有用的:我们称 为 层神经元的带权输入。方程(25)有时候会以带权输入的形式:。同样要指出的是 的每个元素是 ,其实 就是第 层第 个神经元的激活函数的带权输入。
其实,这就是让我们使用之前的矩阵下标表示 的初因。如果我们使用 来索引输入神经元, 索引输出神经元,那么在方程(25)中我们需要将这里的矩阵换做其转置。这是一个小的改变,但是令人困惑,这会使得我们无法自然地讲出(思考)“应用权重矩阵到激活值上”这样的简单的表达。
2 代价函数的两个假设
- 代价函数是训练样本上每个代价函数的均值:反向传播实际是对单个训练样本计算偏导数,然后对所有训练样本求平均,即。
- 代价函数可以表示为网络输出的函数:这使得我们可以固定输入训练样本,并将代价函数视为仅依赖于输出激活值的函数。
3 阿达马(Hadamard)乘积
阿达马乘积(舒尔积)是按元素进行的向量乘积运算。虽然在其他领域中不常见,但在反向传播中非常有用,因为它允许我们逐元素地操作矩阵和向量,从而简化了计算过程。
假设和是两个维度相同的向量,那么表示按元素乘积.举例如下:
3. 反向传播的四个基本方程
反向传播算法的核心在于以下四个基本方程,它们描述了如何从输出层反向传播误差,并计算每层的梯度:
-
输出层误差:计算输出层每个神经元的误差。
-
误差反向传播:利用当前层的误差计算前一层的误差。
-
偏差的梯度:计算偏差对代价函数的梯度。
-
权重的梯度:计算权重对代价函数的梯度。
4. 反向传播算法的步骤
反向传播算法的具体步骤如下:
4.1 输入设置
为输入层设置激活值,即将训练样本输入到网络中。
4.2 前向传播
计算每层的带权输入(即加权求和)和激活值。前向传播步骤将输入数据通过网络传递,最终计算出输出层的激活值。
4.3 输出层误差计算
根据网络输出和期望输出(标签),计算输出层的误差。这一步通过比较实际输出与期望输出之间的差异,得出输出层的误差。
4.4 误差反向传播
从输出层向前一层一层地计算误差。利用输出层误差,通过反向传播算法,将误差逐层向前传播,计算每层的误差。
4.5 计算梯度
利用误差计算代价函数对权重和偏差的梯度。这一步通过利用前向传播和反向传播得到的值,计算出代价函数相对于网络中每个权重和偏差的偏导数。